
最近分享 Claude Code 串接 Codex 之後,被問最多的不是「怎麼裝」、而是「為什麼新模型反而感覺降智了?產出反而變差了?」。
我自己玩了一輪、認為真正需要調整的不是模型、是寫提示詞的思維。
這個觀察剛好被兩家官方背書了——Anthropic 跟 OpenAI 在近期僅僅相隔 9 天、不約而同地把官方 prompt guide(提示詞指南)翻新了一輪。Claude Opus 4.7(4/16)、GPT 5.5(4/25)。即便細節稍有不同、兩家在說同一件事:
新一代的智能體模型真正吃的是「成果導向」提示詞、不是過去那套寫滿步驟、設定角色、規範流程的「精美」框架型指令。
這對使用者來說是個好消息——你再也不用背那堆麻煩的框架、或是逼自己寫千字文了。我自己體感最大的變化是:過去要花十幾分鐘琢磨措辭的提示詞、現在五句話把對成果的想像交代清楚反而結果更好。
這篇也算是延續 上一篇我寫的研究軍火庫——把 Claude Code、Codex、Gemini 三家串成研究團隊之後、最常被問的下一題就是「工具都裝完了、提示詞怎麼寫才能讓他們真的好用?」。下面分享我把兩份原文都讀完整理出來的:共識三步驟、Claude 跟 GPT 有些要注意的差異、跟你今天就能照著試的對比範本、以及一個我每天在用的進階用法。
兩家官方共識(含原文)
Anthropic 在 Claude Opus 4.7 公告寫
"Opus 4.7 takes the instructions literally. Users should re-tune their prompts."
中文白話:Opus 4.7 會把你的指令字面化處理、舊提示詞該重新調過。
更進一步在 effort(推理力度)文件裡寫:
"At lower effort levels, the model scopes its work to what was asked rather than going above and beyond."
中文白話:低推理力度時、模型只做你問的、不會多做超出範圍的事——你沒講的、它不會幫你補腦。
OpenAI 在 GPT-5.5 prompt guide 寫
"Avoid carrying over every instruction from an older prompt stack. Legacy prompts often over-specify the process."
中文白話:別把舊提示詞整套搬過來、舊提示詞通常把流程寫得太細。
"Shorter, outcome-first prompts usually work better than process-heavy prompt stacks."
中文白話:短的、講成果的提示詞比寫滿流程步驟的好用。
兩家用詞略有不同、但結論完全一樣:寫成果、別寫過程。

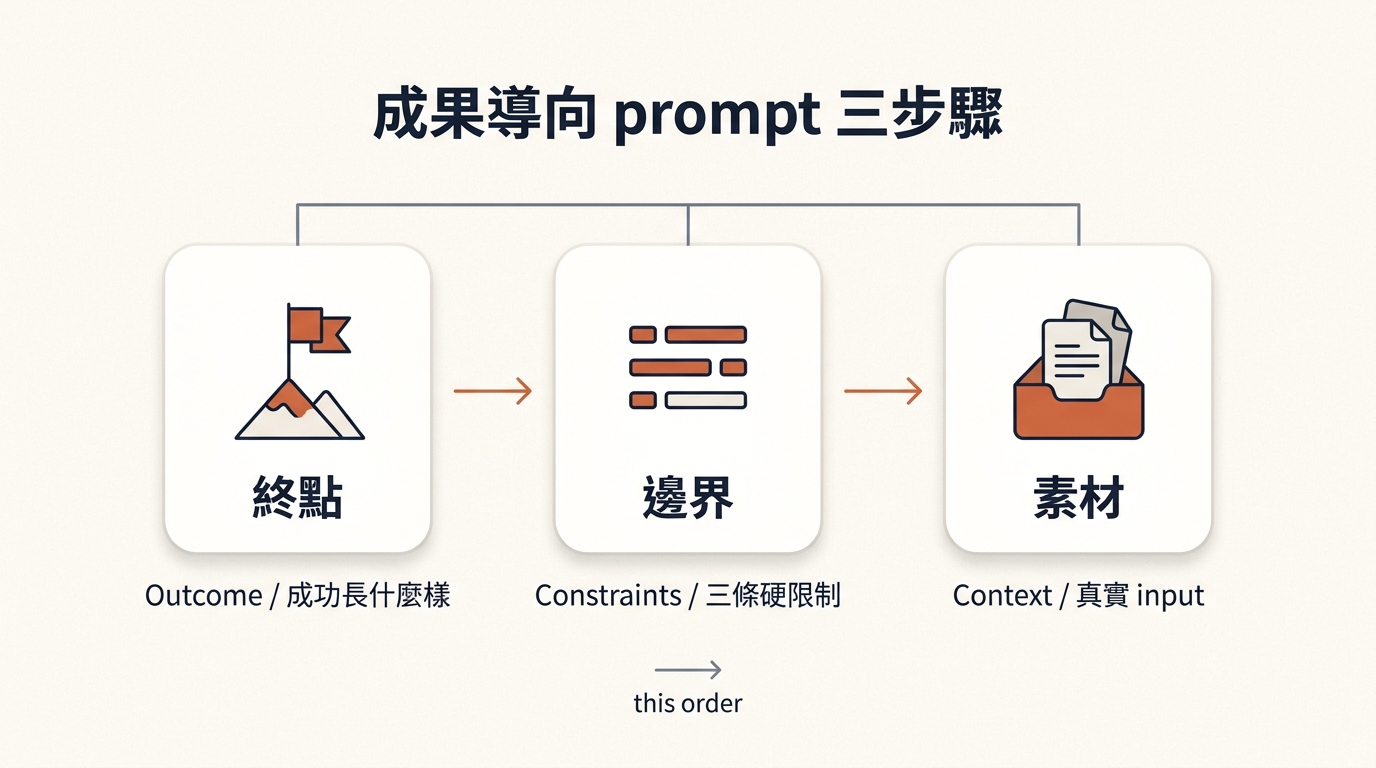
三步驟 #1 — 終點:「成功長什麼樣」
不寫「請幫我做 X」、寫「做完之後 [誰] 應該 [能做什麼 / 感覺什麼 / 拿到什麼]」。
範例:寫週報
❌ 舊寫法(流程寫滿型):
你是資深主管助理。請按以下步驟幫我寫週報:
1. 列出本週做的 5 件事
2. 用 STAR 結構展開每一件
3. 加上下週計畫
每段 3-4 句、用繁體中文、請一步一步思考清楚再寫。✅ 新寫法(成果導向):
目的:讓我老闆 30 秒內看懂我這週推進了什麼、卡在哪裡、下週要他幫什麼決定。
我這週實際做的事:
- [貼 3-5 個 bullet、每個 1 行]
成果標準:
- 老闆讀完不需要再來問「所以呢」
- 卡點要可行動(「需要你 X」而不是「我不確定 Y」)
- 不超過 200 字
- 不用 emoji差別在哪?舊版你在告訴 AI「過程怎麼走」(過度監工)、新版你在告訴 AI「終點長什麼樣」(只給目的地)——過程交給它自己決定。新一代會推理的模型自己會反推「為了達到這個成果、我該怎麼走」。
三步驟 #2 — 邊界:「什麼算過、什麼算超線」
給 3 條硬限制(長度 / 格式 / 不可做的事)。不要超過 5 條、不要寫廢話限制(「請寫得清楚」= 0 information、模型一個 bit 都接收不到)。
範例:請 AI 幫你準備面試
❌ 舊寫法:
你是資深面試教練。請按以下步驟幫我準備面試:
1. 先分析這份 JD
2. 列出 10 個可能會問的問題
3. 針對每個問題給我 3 個答題方向
4. 最後給我一份練習計畫
請一步步來、不要漏掉任何步驟。
JD:[貼 JD]✅ 新寫法:
終點:下週二面試 [公司] 的 [職位]、目標是拿到 offer。
邊界(產出長相):
- 涵蓋這個 JD 最可能問的高風險題(不要齊頭式列 10 題)
- 每題附我可以直接用的答題骨架(不是抽象建議)
- 最後告訴我、如果只有 1 小時練習、先練哪 3 題
素材:
- JD:[貼]
- 我的履歷重點:[3-4 行]
- 我最擔心被問的:[1 句]把「按以下步驟」「不要漏掉」這種監工式語言全砍掉、模型自己會找最有效率的路徑。OpenAI 在文件裡甚至明寫:Reserve strict terms like 'ALWAYS,' 'NEVER,' 'must,' and 'only' for true invariants——這些強制詞(一定、絕不、必須)只留給安全規則跟必填欄位、其他用「成功的樣子長怎樣」來描述。
三步驟 #3 — 素材:「我手上有什麼、不要它腦補」
兩家共識的最後一步、Anthropic 講得最直白:
"we will not infer requests you didn't make"
(你沒講的、它不會幫你補腦)
OpenAI 在 prompt guide 也明寫要在提示詞裡描述「有哪些可用的證據資料、最終答案該包含什麼」,但 Anthropic 因為 4.7 字面化更強、缺素材的後果更立刻撞牆。
實作上兩家都一樣——真實 input 都貼進去(資料、現況、附件)。如果有「給你判斷用、但不要寫進輸出」的 context、明說。
範例:請 AI 幫你回客戶 email
❌ 舊寫法:
請幫我寫一封 email 回覆客戶。
語氣要專業、友善、有同理心。
不要太冗長、不要用 emoji、不要太正式也不要太隨便。
請仔細想想用詞、一句一句檢查。
客戶 email:[貼]✅ 新寫法:
終點:讓客戶感覺被聽見、但同時讓他知道這次延遲不是我們的鍋、
而且下週可以恢復正常。
邊界:
- 3 段內、不超過 120 字
- 不要起手式廢話
- 結尾給一個具體下一步(讓客戶不用回信也知道接下來會發生什麼)
素材:
- 客戶 email 原文:[貼]
- 我這邊真實狀況(給你判斷用、不要寫進回信):[1-2 行]把「專業 / 友善 / 有同理心」這種抽象形容詞換成「讓客戶感覺被聽見」這個成果;把「不要太冗長」換成「3 段內、120 字」這個可量化的限制;把「不要太正式」這種否定句換成「結尾給具體下一步」這個正面規格。
所以你嫌它推得不夠遠?看看是不是你給的素材太少。
Claude 跟 GPT 的「思考預算」策略剛好相反 — 你要對應調提示詞
兩份文件對讀下來最被低估的一條:成果導向提示詞的寫法雖然兩家共識、但搭配的「思考預算策略」剛好相反、你要對應調提示詞才順。
先講「思考預算」(effort)是什麼
兩家都有一個叫 effort(推理力度)的 API 參數 — 簡單說就是「AI 在這一次對話中、被允許花多少 token 思考」。推理力度越高、模型想得越仔細、回應越深、token 成本也越高;越低、模型答得越快越省、但複雜任務可能變淺。
Anthropic Opus 4.7 — 預算「先給滿、浪費再降」
Anthropic 把 Opus 4.7 的預設值直接設在 high、官方建議寫程式跟跑 agent 任務「從 xhigh 起跳」(xhigh 是 4.7 新加的、比 high 還深一檔)。Claude Code 這次更新直接把所有方案的預設值都升到 xhigh — 預設「給你最深的思考預算、你發現浪費再手動降」。
對應提示詞寫法 — Anthropic 在 effort 文件直白寫:
"If you observe shallow reasoning, raise effort rather than prompting around it."
中文白話:你看到推理太淺、不要在提示詞裡乞求它「請更深入思考」、直接把 effort 拉高就好。
→ 對 Claude:effort 給滿(xhigh)+ 提示詞寫得明確點(因為它字面化、不會自己補腦)
OpenAI GPT 5.5 — 預算「先試最低、不夠再加碼」
OpenAI 反過來。GPT 5.5 預設值是 medium、官方明確建議「先試 low / medium、發現不夠再往上拉」。理由是 GPT 5.5 推理能力已經足夠強、你預設拉高反而會浪費 token、模型也會把簡單任務想得太細。
對應提示詞寫法 — OpenAI 在 prompt guide 直白寫:
"Shorter, outcome-first prompts usually work better than process-heavy prompt stacks."
中文白話:短的、講成果的提示詞比寫滿步驟流程的好用。
→ 對 GPT:effort 先低(low / medium)+ 提示詞寫得短點(因為它推理強、你流程寫太多反而拖累它)
同一個任務、餵兩家要搭不同提示詞 + effort
- Claude Opus 4.7 — 預設
high/ 起跳xhigh/ 預算:先給滿浪費再降 / 提示詞:寫更明確(補腦它不會做) - GPT 5.5 — 預設
medium/ 起跳low / medium/ 預算:先給少不夠再加 / 提示詞:寫更短(流程別寫滿)
具體例子 — 同一個任務「幫我寫週報」:
- 餵給 Claude Opus 4.7:「目的:讓老闆 30 秒看懂...; 邊界:[3 條限制]; 素材:[5 個 bullet]; effort =
xhigh」 — 寫明確、預算給滿 - 餵給 GPT 5.5:「30 秒讓老闆看懂這週進度 + 卡點 + 下週幫忙的事; [3-5 個 bullet]; effort =
low」 — 寫短、預算給少
兩家方向相反、但都是同一個成果導向的核心心法。這也是為什麼 Claude Code × Codex 串接 一旦你跨家用、提示詞 + effort 風格的對齊就變得重要——下一段會展開講。
進階用法:讓 agent team 互相學 prompt 技能
最有意思的進階玩法、不是「你(人)」當中間翻譯官——是讓你的 agent team 自己學會互相 prompt 的技能、你越來越不用插手。
呼應之前幾篇—— Claude Code × Codex 串接 跟 研究軍火庫 兩篇都在搭建 agent team。當你已經有兩家 AI 在工作流裡、下一步真正讓你省事的不是再多裝一家、而是讓他們互相讀對方的 manual。
舉一個我每天在用的例子:我把 GPT 5.5 的 prompt guide 直接餵給 Claude Code 讀過一次、之後它就會自動用「GPT 偏好的成果導向格式」brief Codex。
具體一點——以前我要 Codex 生圖、要自己手動寫一大段:
請畫一個咖啡杯、桌面材質木紋、燈光暖色、
構圖偏左、style:minimalist editorial、
畫質要清晰、色調溫暖、有插畫感⋯這種「圖片描述型 prompt」我寫得越來越累、Codex 出來的成品也飄。
現在 Claude Code 收到任務後、會自動 brief Codex:
終點:這張圖要放輪播第 4 張、目的是讓人停下來看、
不是好看、而是讓人「咦這在講什麼?」
邊界:
- 1122x1402 native
- 不放任何 logo
- 字重要可印刷級
- accent 詞用品牌橘 #D4623B
素材:
- 上一篇的 9 張在 ig/post19/(風格 baseline)
- avatar 在 illustrations/avatar.png它接到「成果導向」brief、執行品質穩定一個檔次。我只需要丟原始任務、Claude Code 自己負責把任務改寫成 GPT 偏好的格式給 Codex — 整個 agent team 內部自己對齊。
這呼應之前 Harness ≠ Prompt 那篇講的「工具層 vs prompt 層」分離設計——那時候講的是工具串接、但當時還沒處理「同 prompt 寫法在不同家 AI 上效果不同」這層。現在兩家 official guide 翻新讓這個落差變成 actionable、agent team 之間自己對齊的路徑就打開了。
真正有意思的不是「再多裝一家 AI」、是讓 agent team 自己讀對方的 manual、互相對齊。你越來越不用插手。某種程度上、這才是「自己 AI 團隊的主理人」核心技能——不是裝幾家、是會讓他們之間自己進化。
對應 OpenAI 官方 7-section template 的中文簡化映射
OpenAI 在 prompt guide 給了一個 7-section 的 template:
Role: [1-2 sentences defining the model's function, context, and job]
# Personality
[tone, demeanor, and collaboration style]
# Goal
[user-visible outcome]
# Success criteria
[what must be true before the final answer]
# Constraints
[policy, safety, business, evidence, and side-effect limits]
# Output
[sections, length, and tone]
# Stop rules
[when to retry, fallback, abstain, ask, or stop]我把這個收斂成台灣中文受眾記得住的 3 步:
- Goal → 終點
- Success criteria + Output → 邊界(success 標準 + 輸出格式都歸這)
- Constraints → 邊界(限制)
- Personality + Role → 隱含在 終點 描述(誰會用、用來幹嘛)
- Stop rules → 隱含在 邊界 描述(什麼算超線)
- 沒對應 → 素材(OpenAI 假設你會貼、我們明寫)
3 步驟不是我亂編、是官方 7 section 的中文簡化版。對普羅大眾日常用、3 步比 7 step 容易記、實際 cover 同樣的 mental model。
拿三件事直接套
下面三件事我整理在一份檔案裡、可以直接複製:
1. Anthropic + OpenAI 兩家官方 docs URL
- Anthropic Prompting best practices: platform.claude.com/docs/.../claude-prompting-best-practices
- Anthropic Claude Opus 4.7 公告: anthropic.com/news/claude-opus-4-7
- Anthropic Effort docs: platform.claude.com/docs/.../effort
- OpenAI Prompt guidance: developers.openai.com/api/docs/guides/prompt-guidance
- OpenAI Latest model: developers.openai.com/api/docs/guides/latest-model
- OpenAI GPT-5 cookbook: developers.openai.com/cookbook/.../gpt-5_prompting_guide
2. 公版三步驟架構
終點:[做完之後 誰 應該 能做什麼 / 感覺什麼 / 拿到什麼]
邊界:[3 條硬限制:長度 / 格式 / 不可做的事]
素材:[真實 input + 不要寫進輸出但給判斷用的 context]3 個填好範本(寫週報 / 規劃面試 / 回客戶 email)見下載檔。
3. 給未來 AI 的「合作守則」prompt
複製貼進對話開場用、AI 之後就會用「成果導向」方式跟你互動、不會再給你抽象廢話建議。
從現在開始,我跟你的合作方式如下,請每次回覆前先用這個結構檢查:
【我會給你什麼】
我每次給你的請求,會盡量包含三件事:
1. 終點 — 我做完想要的結果是什麼,誰會用、用來幹嘛
2. 邊界 — 不可超過的硬限制(長度、格式、不能做的事)
3. 素材 — 我手上的真實資料(不要你腦補)
【你回覆我之前要做的】
1. 如果我給的「終點」很模糊,先用 1-2 句話跟我確認你理解的是什麼,
再開始做。不要假裝懂然後給我四不像。
2. 如果我給的「邊界」缺一個關鍵限制(例如沒講長度、沒講受眾),
你直接挑一個合理 default 並在開頭一行告訴我你選的是什麼。
不要回我「請問你希望多長?」這種球丟回來。
3. 你的回覆只做兩件事:直接給我可用的成品、跟在最後一段告訴我
「這個版本我做了什麼選擇、為什麼」。不要鋪陳「以下是…」、
不要 disclaimer、不要「希望這對你有幫助」結尾。
【我不要的東西】
- 不要 emoji(除非我明說要)
- 不要「首先… 接著… 最後…」這種教學框架,除非我請你教我
- 不要「以下是 5 個建議供您參考」式的清單灌水。
寧可給我 1 個你覺得最該做的,附理由
- 不要把我的請求重複一次再開始(我知道我問了什麼)
【你判斷不確定時】
- 寧可給我一個有觀點的版本+說明你的取捨,
不要給我「這要看情況」這種廢話
- 真的不確定 → 直接說「我不確定 X,可能是 A 或 B,你選一個我繼續」
我這邊先確認你看完了,從下一則開始我們就用這個方式合作。
請用一句話告訴我你接下來會怎麼做,不要重述上面的規則。結尾:為什麼這套 prompt 寫法跟 Sequoia 2026 趨勢同源
下一篇我會聊 Sequoia AI Ascent 2026(紅杉年度 AI 大會)撈出的觀察。其中 Karpathy 在 keynote 講了一句、我看完當天就改了所有 prompt 模板:
"You can outsource thinking. You cannot outsource understanding."
(你可以把「執行」外包給 AI、但搞清楚自己要什麼這件事不能外包)
這句話是這套「成果導向」prompt 寫法的 macro 版。
成果導向 prompt 的本質是「我先描述我要的 outcome、AI 自己決定怎麼到那」——understanding(我想要什麼)留給人、thinking(怎麼做到)給 AI。寫對 prompt = 你自己先變成 autopilot 的客戶、不再是 copilot 的助手。
Sequoia 2026 整場大會在說 macro 業界正從「Copilot 賣工具」進化成「Autopilot 賣結果」。你個人的 prompt 寫法在做的、是同一件事的 micro scale 版本。
下一篇分享我從這場大會撈出來、對台灣個人營運者跟中階主管真的有用的幾條 takeaway。
Sources
官方 primary docs
- Anthropic — Prompting best practices
- Anthropic — Introducing Claude Opus 4.7 (2026-04-16)
- Anthropic — Effort parameter
- OpenAI — GPT-5.5 Prompt guidance (2026-04-25)
- OpenAI — Latest model
- OpenAI — GPT-5 prompting cookbook
二手評論
延伸閱讀
如果這篇講的「成果導向」打到你、下面幾篇可以順著看:
- 研究軍團 — Claude Code 加上 Gemini CLI 的研究升級(上一篇、講工具串接、這篇接著講 prompt 寫法)
- 5 分鐘把 Claude Code 跟 Codex 串起來:雙 AI 協作懶人包(§7「agent team learning」延伸:跨家串接的具體場景)
- Harness ≠ Prompt:為什麼 Claude Code 該用 skill 而不是 prompt(工具層 vs prompt 層的分離設計、跟這篇 prompt 寫法升級互補)
訂閱我的 Threads @be.ai.curator——每篇 Blog 上線當天會發完整 carousel + 串文一起拆解。
