副標:搜尋工具不是模型的附屬、是模型答案好壞的根。我用 28 題對比 3 個搜尋工具、再用 3 題對比自己拼的「更聰明方法」跟 Anthropic 自帶 — 兩場都翻車、學到兩條紀律。
趕時間版(給沒空看完整篇的)
- 起心動念:上禮拜同一個問題(「2026 Anthropic 跟 OpenAI 誰 API 比較便宜」)我問 ChatGPT、Claude、Perplexity 三家、數字差三倍。挖一輪才知道問題不在模型、在底下用的搜尋工具
- 拉了兩場 PK:14 種題目 × 28 題 × 3 個工具(第一場 PK 看能力地圖)+ 3 個硬骨頭題目 × 3 個方案(第二場 PK 看自製方法 vs 自帶)
- 三件意外的事:Tavily 完整度倒數第一、我自己拼的方法輸 1.58 分、其中一題自信地寫錯五倍誤差
- 兩條紀律:表面「選工具不靠官網廣告、自己拉去 PK」;更深「自己拼的也要驗證、沒驗證的設計都是安慰劑」
- 新版工具選用規則:Anthropic 自帶搜尋升 default、Grok / Gemini 搜尋是補位
起心動念:三家 AI 答案差三倍
事情是這樣。
上禮拜有人 LinkedIn 私訊問我「2026 Anthropic 跟 OpenAI 哪家 API 比較便宜」。
我順手打開三個 AI 助手同時問:ChatGPT、Claude、Perplexity。
結果三家給的數字差三倍。
換五種問法(加 context、加比較條件、限制 token 範圍)、落差還在。

挖一輪才發現問題不在模型。
每個 AI 助手底下用了不同的搜尋工具:ChatGPT 用 Bing 跟自己的後端、Claude 自帶搜尋走 Anthropic 自家後端、Perplexity 自己有一套抓資料的方法。
每個搜尋工具有自己的索引、自己的排序邏輯、自己抓資料的偏好 — 每個工具都有自己的盲區。
換 prompt 解不了這個問題、換工具才是真解。
這就是我這個月想升級整套搜尋系統的起點。
為什麼搜尋工具這層對日常工作很重要
這幾年我自己每天用 AI 找資料。寫 blog 寫 LinkedIn 寫提案、研究新的 SaaS 工具、看 KOL 想引用一句話、寫競品比較 — 全部都依賴底下的搜尋層。
最常翻車的四個情境:
1. 想核對一個數字
寫文章引用「Anthropic 2026 Q1 營收 10 億」、要找權威出處確認。Anthropic 自帶搜尋有時抓到 SEO blog(轉貼)而不是原始 8-K filing。
2. 看 KOL 講過的一句話想找原話
看到 Karpathy 在某 talk 講「software 3.0」、想找完整原話 + 影片時間點用在 blog。X 上的 thread 是片段、需要影片字幕 + 講稿一起對才能找到原話。
3. 研究 SaaS 工具的最新定價跟新功能
評估要不要訂 Cursor / Windsurf / Claude Code、要看 2026 第二季各家定價結構(每席 / 點數 / 額度)。如果搜尋抓的是去年快照、會給去年資料、誤導判斷。
4. 寫競品比較想看四家在某個面向各自怎麼說
4 家 × 4 個面向 = 16 格。單家搜尋工具常常某幾格漏掉(特別是「冷門品牌 + 特殊功能」這種長尾組合)。
這四件事我都翻過車。
不是模型亂編、是搜尋工具沒抓到對的東西給模型看。
第一場 PK:14 種題目 × 3 個工具 = 28 題能力地圖
為什麼用「能力地圖」、不是「排行榜」
AI 模型自己在做 PK 的時候、早就放棄「誰最強」這種說法。MMLU 不是一條排名、是 57 個學科 × 多個模型的對比表。SWE-bench 不是「最強寫程式 model」、是「在這個 repo 修這種 bug 的成功率」。
沒有單一數字能講「誰最強」、只能講「在哪種題目上強」。
我把這套套到搜尋工具:
- 14 種題目類型(X / Threads/IG / Reddit / HN / Google 通用 / 趨勢新聞 / 個人 blog/Substack / 付費牆 / 動態網站 / 官方文檔 / YouTube / GitHub 程式碼 / 學術論文 / 台灣媒體)
- 3 個工具對打(Gemini 搜尋 / Grok 搜尋 / Tavily 搜尋)
- 每種題目出 2 題(一題穩定的 / 一題時敏的)= 28 題
- 每題派給 3 個工具同時跑、總共 84 次
為什麼這場 PK 沒包 JINA / Firecrawl / Anthropic 自帶
讀到這邊一定有讀者想問 — 我自己這一年陸續用過 JINA / Firecrawl / Tavily / Grok / Gemini 搜尋 / Anthropic 自帶 6 家、為什麼第一場 PK 只比 3 家?
誠實版:
- JINA:原本是我整套系統的主力(把網址讀成乾淨文字)。免費額度上個月用完之後改 anonymous 兜底、不是主力、所以沒進這場 PK。
- Firecrawl:是「把網址讀成乾淨文字」的工具、不是「主動搜尋」工具。它跟 Tavily / Gemini 搜尋不在同一層。它在「抓全文」這層強、見後文真正能 work 的拼法那段。
- Anthropic 自帶搜尋:第一場 PK 沒包、因為我跑 Python 腳本沒辦法直接 call Claude Code 內建工具。但在後面的第二場 PK 有對比。
第一場 PK 結果:能力地圖出爐
跑完 28 題 × 3 工具 = 84 次、再請 Gemini Pro 評分(評每題的完整度、具體度、出處可不可驗證)。
幾個意外的發現:
發現 1: Tavily 官網廣告 vs 實測完全相反
- 官網廣告:「The search API designed for AI agents」(為 AI 設計的搜尋 API)
- 實測完整度:1.54 / 5(倒數第一)
- 實測具體度:1.36 / 5(差距甚大)
- 14 種題目只在 GitHub 程式碼這 1 格拿第一
- 速度 4.4 秒最快、但「快但答案不對」沒意義
Tavily 在我的場景就是不適合。它的價值或許在「機器讀的網址列表」、不是「人看的可用答案」。
發現 2: Gemini 搜尋是最穩的單一工具
- 14 種題目贏 8 種
- 在內容深度題(blog / 動態網站 / 台灣媒體 / 趨勢新聞 / 官方文檔 / YouTube / HN / Threads-IG)幾乎全勝
- 不要錢(Gemini API 在免費額度內)
- 平均回應時間 10 秒可接受
發現 3: Grok 搜尋不只強 X 內容
- 14 種題目贏 5 種(Google 通用 / Reddit / X / 付費牆 / 學術論文)
- 在「需要跨多個出處推理」的題目特別強(Grok 4.1 Fast 模型本身的推理深度)
- 代價是平均回應時間 50 秒 + 一題大概 0.05 美金
- 適合「品質優先、不在乎慢」場景
完整能力地圖見一頁版(lead magnet)。先帶到第二場 PK — 翻車最痛的那場。
第二場 PK:我自己拼的方法 vs Anthropic 自帶 — 自我打臉
拼的時候自己很滿意(事後看是被自己騙)
拿到第一場 PK 的能力地圖之後、我想再升級一層。
設計了一個三層工具選用規則:
- 第一層:簡單問題用 Anthropic 自帶搜尋
- 第二層:依題目類型派 PK 贏家單跑(X 走 Grok / Google 通用走 Gemini 搜尋)
- 第三層:硬骨頭題目跑「對抗式拼裝」 — 三個搜尋工具同搜 + Voyage 排序器排第二輪 + Gemini 把前 10 條合成最終答案
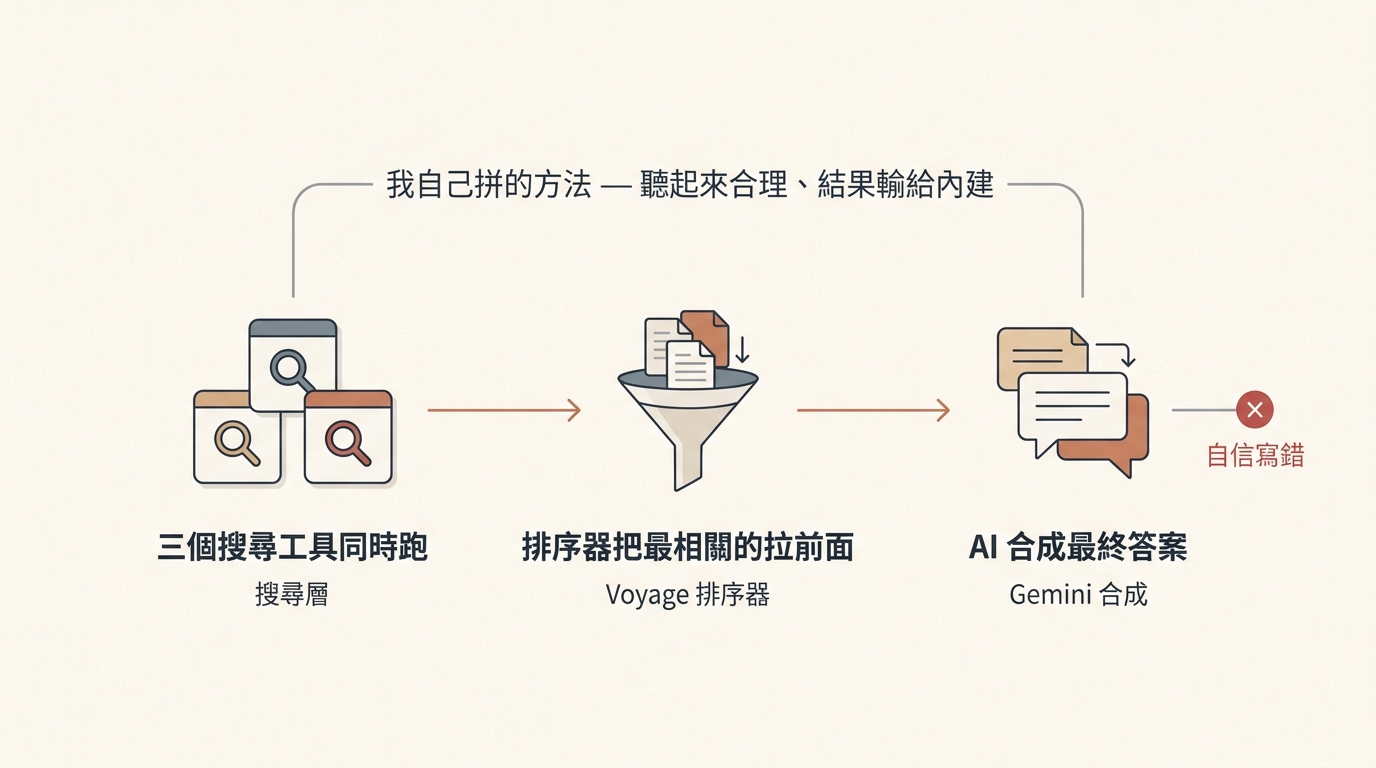
聽起來怎麼想都該贏單一搜尋對吧。多家來源、有排序、有合成。
我以為勝定了、差一步就把這個方法寫進每天用的工作守則。
幸好被一個關鍵問題打斷 — 我憑什麼認為它會贏?
第二場 PK 設計
選了 3 個硬骨頭題目(涵蓋 quote 引用 / 競品深度對比 / 核對事實基準題)、對比三個方案:
- A:Anthropic 自帶搜尋
- B:Gemini 搜尋單跑(單工具基準)
- C:我設計的拼裝方法
同一個 AI 評分(Gemini Pro)、同 4 個面向(完整度 / 具體度 / 出處可驗證度 / 整理品質)。
結果讓我重新看自己的設計直覺
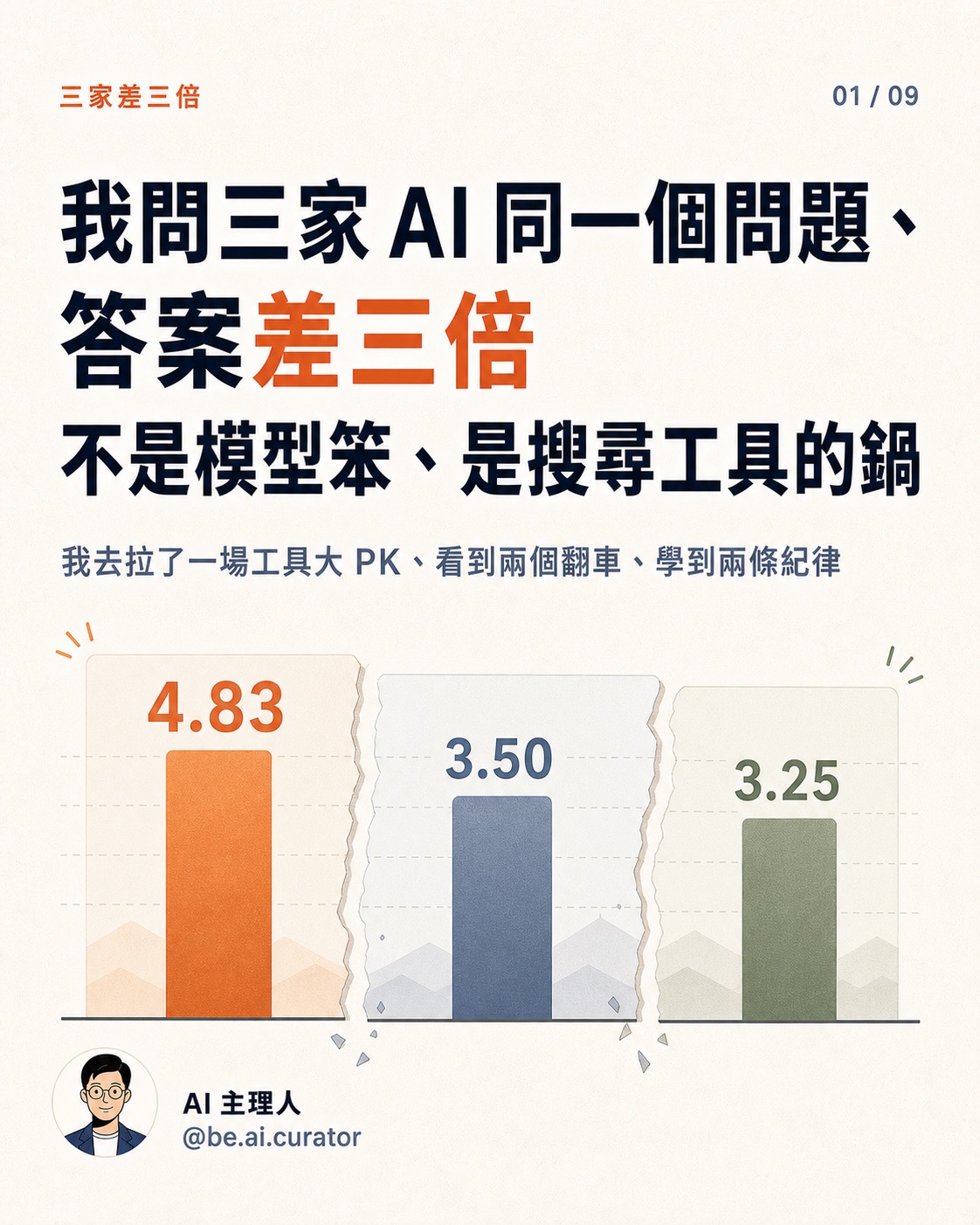
方案 | 完整度 | 具體度 | 出處 | 整理 | 平均
A — Anthropic 自帶 | 4.67 | 5.00 | 5.00 | 4.67 | 4.83 ⭐
B — Gemini 搜尋單跑 | 4.67 | 4.33 | 1.00 | 4.00 | 3.50
C — 我自己拼的 | 2.00 | 2.33 | 5.00 | 3.67 | 3.25 ❌Anthropic 自帶三題全勝。我精心拼裝的方法三題全敗、平均倒數第一。
最痛的是其中一題:
我問「Anthropic Claude Opus 4.7 釋出日期 + 一次能讀多少字 + 主要新功能」
- A 自帶搜尋答:1M(對)、2026-04-16 釋出(對)、5 個新功能
- C 我拼的方法答:200K(錯、差五倍)、2026-04-16 釋出(對)、3 個新功能
我設計的方法自信地寫錯一個五倍誤差的數字。
為什麼這個聽起來合理的設計會輸
挖完之後找到三個原因:
1. 排序器只看標題跟網址、沒看內文
我送給排序器(Voyage)的東西是「標題 + 網址 + 前 300 字摘要」、不是全文。排序器是看「題目跟資料的相似度」、但只看摘要資訊不夠、所以排錯位置、把對的出處排到後面。
2. 合成 AI(Gemini)也沒原文可看
收到排好的前 10 條、也只看到標題 + 網址、合成 AI 只能照標題編答案。看不到內容、當然會自信地亂寫。
3. Anthropic 自帶搜尋已經做完「全文 + AI 看內容 + 整理重點」全套
它的後端早就做完「抓全文 + AI 看內文 + 整理結構」全流程。我自己拼的方法重做這件事、卻少了「抓全文 + AI 看內文」最關鍵那步。等於用更慢的方式做出爛三分之一的版本。
真正能 work 的拼裝方法
如果以後要重啟、需要這樣:
題目
↓
Gemini 搜尋 + Grok 搜尋(拿到大概 30 條出處)
↓
Firecrawl 把前 30 條的全文抓回來 ← 這步是關鍵(Firecrawl 在這層)
↓
Voyage 排序器看「題目 vs 全文」排第二輪 → 拉前 10 條
↓
Claude / Gemini 看著前 10 條全文合成最終答案這個拼法包含 Firecrawl 當「抓全文層」、不是當「搜尋層」。Firecrawl 在搜尋層比不過 Tavily / Gemini 搜尋、但在「網址→乾淨全文」這層它強項。
但這需要:Firecrawl 月費方案(19 美金)、60-120 秒等待、跟自帶比是否真贏還要再拉一場 PK。
不確定值不值得、暫時擱置。
兩條紀律

表面:選工具不靠官網廣告、要自己拉去 PK
- 廠商定位常常是 anti-signal — 講越大聲、實測落差越可能大
- 評估新工具不准只看 README / 定價頁 / 廠商 demo
- 必拉「自己場景 PK」(你真實會用的 5-10 題)
- 「永久免費」「無限制」「最強」這類廣告話術自動觸發驗證紀律
更深:自己拼的也要驗證
這層比表面更重要。
我自己設計的三層工具選用規則 + 拼裝方法、邏輯聽起來合理、實作也跑通了。如果沒先做第二場 PK 就直接寫進工作守則、會發生兩件事:
- 每次「嚴謹研究」都跑一次比自帶差的拼裝、得到錯誤答案還以為「我用了更厲害的方法」
- 錯誤往下游污染所有依賴它的內容(blog 核對事實 / Post 主題定稿 / 競品比較)
自己拼的東西自己會偏愛、是天性。
所以更要設一道強制機制 — 用最簡單的既有方法當對照組、新方法沒明顯贏(5 分制差 0.5 分以上)就撤。
這條紀律救了我這次沒把錯的方法寫進每天用的工作守則。
我新版的工具選用規則(直接 inline 給你抄)
跑完兩場 PK、我把自己的搜尋工具選用規則改成這樣:
- 預設 / 不確定 → Anthropic 自帶搜尋(第二場 PK 贏家、不要錢、整合最深)
- Blog 主文核對 / 競品深度比較 / 找原話 → Anthropic 自帶搜尋(高風險場景自帶碾壓拼裝)
- 結構化網址列表(給程式吃) → Gemini 搜尋(gsearch)
- X / Twitter 內容 → Grok 搜尋(grok-search)
- 付費牆 / 學術論文 / Reddit 深度 → Grok 搜尋(第一場 PK 完整度 5.0 贏家)
- Google Workspace / 長 PDF → Gemini CLI(OAuth、自帶沒辦法存私人 Workspace)
- GitHub 程式碼深度 → Tavily(免費額度內、第一場 PK 唯一贏家題型)
- 網址→乾淨全文 → Firecrawl(未來重啟拼裝必含)
- 影片字幕 → youtube-transcript
- 登入站爬取 → browser-sessions
撤掉的設計:自己拼的對抗式拼裝 — 第二場 PK 證明輸給自帶。Voyage 排序器在「只看標題 + 網址」場景沒戰場、暫降「擱置」。
延伸閱讀
給未來的我
這次學到最重要的不是哪個搜尋工具贏。
是「我自己設計的東西要自己驗證」這條紀律。
如果說過去一年我建立的習慣是「動手寫之前先讀過去 baseline」、那這次建立的新習慣就是「動手 deploy 之前先拉一場 PK」。
兩條紀律同根:直覺好聽 ≠ 實測有效。
這篇是寫給也想自己拉 PK 的人看的。完整 PK 腳本跟原始數據我攤平在文章下方的下載卡片裡、可以直接抄去你自己 use case 跑。
下篇我們聊另一個翻車。這個月我拼失敗的東西不只一個。
Benchmark Deep Report — 完整數據攤平給你看
故事講完了。如果你想看真實 raw data 而不是被我消化過的版本、底下是兩場 PK 的完整數據攤平。
第一場 PK 整體分(28 題平均)
28 題分散在 14 種題目(每題型 2 題)、3 個搜尋工具同時跑、共 84 次 API 呼叫。Gemini 2.5 Pro 當評審、評每題的完整度 / 具體度 / 出處可驗證度。
注意 Tavily 速度最快(4.4 秒)但完整度 1.54 倒數第一。快、但答案不對、價值不在搜尋這層。
14 種題目能力地圖(一張圖看完)
每個 cell 是該工具在該題型的完整度(0-5 分)、底色強度反映分數、★ 標每行 winner。一張圖看完三家工具的能力分布。
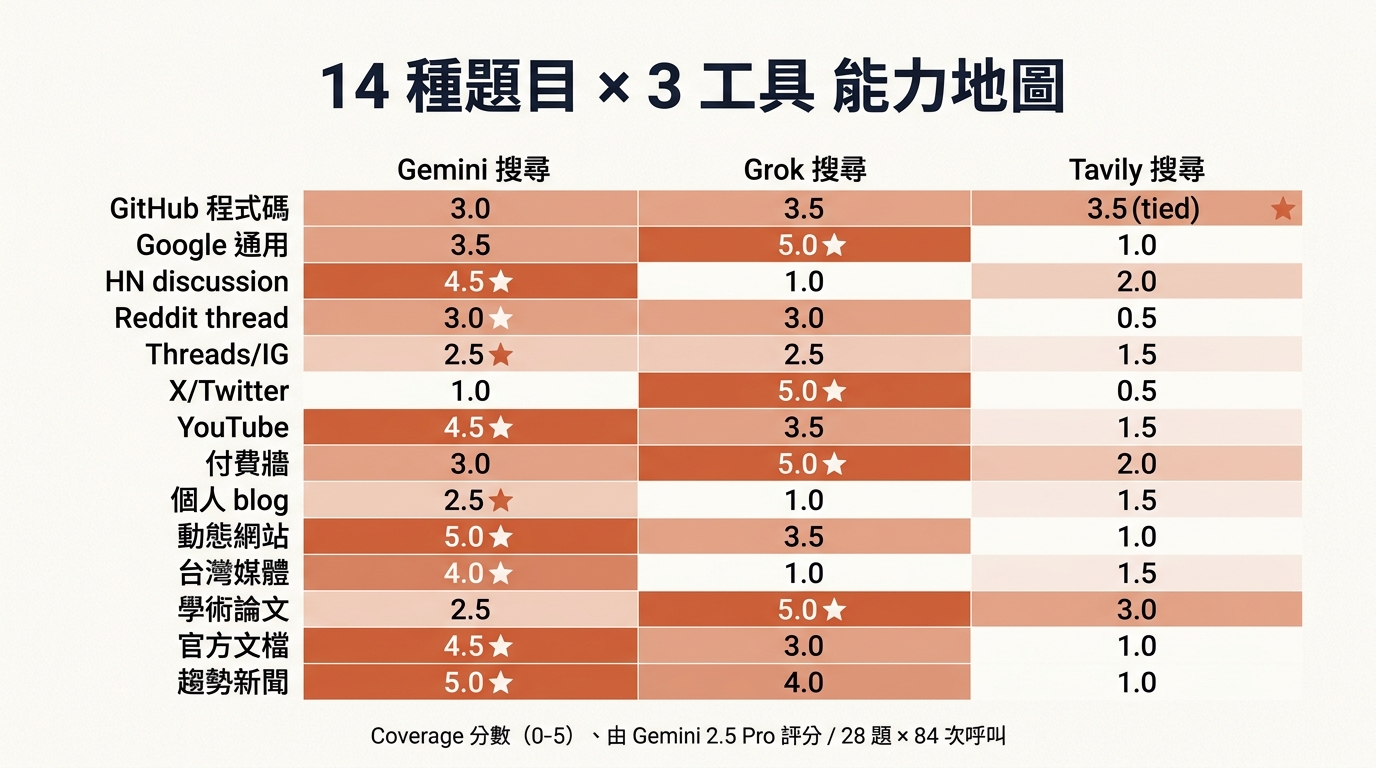
14 種題目 winner 分布
數一下:Gemini 搜尋贏 8 種、Grok 搜尋贏 5 種、Tavily 贏 1 種(GitHub 程式碼跟 Grok tied)。
「能力地圖」這個 framing 重要在哪 — 如果只看 overall 平均分(Gemini 3.46、Grok 3.29、Tavily 1.54)你會以為 Gemini 全面最強。但拉開看 task 維度才看到:X / Twitter 跟 Google 通用是 Grok 完勝、Gemini 連 1 分都拿不到。沒看 task 分布、你會做出錯誤的工具選用決定。
第二場 PK 三題逐題打分(自己拼的 vs 自帶)
3 題硬骨頭、3 個方案、4 個評分面向 = 36 個 cell。Gemini 2.5 Pro 當評審 + 給簡短理由。
題目 m1:Karpathy 2026 Sequoia AI Ascent 原話
題目 m2:Cursor / Windsurf / Cline / Claude Code 四面向比較
題目 m6:Claude Opus 4.7 核對事實基準題
這就是「自信地寫錯」的 evidence — m6 我自己拼的方法完整度 1/5、評審直接標「嚴重幻覺、答案失去參考價值」。同題自帶搜尋 5/5 全勝。我設計的方法不是答得不全、是答得自信地錯。
為什麼三場都輸 — 三個根因
根因 1: 排序器吃的是 metadata、不是全文。我送給 Voyage 排序器的是「標題 + 網址 + 前 300 字摘要」。排序器看不到內容 detail、無法判斷哪條真的有答案。所以排錯位置 — 真正有答案的 source 被排到後面 10 條去。
根因 2: 合成 AI 也沒原文可看。收到排序過的前 10 條、Gemini 看到的只是「title + URL」list、沒有對應全文。合成 AI 只能照標題編答案。Context Window 寫成 200K 就是這樣 — Gemini 看標題「Claude 4.7 release notes」、自己腦補(200K 是過去常見 Claude context size)、寫進答案。
根因 3: Anthropic 自帶搜尋已經做完最關鍵那步。它的後端是「抓 top sources 全文 + LLM 看內文 + 整理結構」三段式。我自己拼的方法重做「整理結構」這段、但少了「抓全文 + LLM 看內文」最關鍵的中間步。等於用更慢的方式做出一個爛三分之一的版本。
把根因翻成一條操作紀律:如果你要拼裝多工具搜尋、必須先 scrape 全文、再做 rerank、再做合成 — 三段不能缺中間。我跳過 scrape 全文這步、所以全敗。
你拿去自己拉一場 PK 的操作 SOP
這場 PK 我用的工程紀律、攤給你 — 你可以拿去自己 use case 跑一場、不需要從零想流程。
- Step 1: 題目集 — 從過去 30 天真實查過的東西採樣 5-10 題(不要用「我覺得讀者會問的」假題)
- Step 2: 評分面向 — 主觀面向(完整度 / 具體度 / 出處可驗證度)AI 判 / 客觀面向(出處信度白名單 / 時敏度 regex / 速度)程式判、兩軌分開
- Step 3: AI 評審用獨立 model — 不要 Claude 評 Claude、Gemini 評 Gemini。我這場 PK 評審用 Gemini 2.5 Pro、被評的是 gsearch / Grok / Tavily
- Step 4: AI 評審 timeout 給 240 秒 — 長提示詞 5-10K 字會超 120 秒。我跑這場 PK 中途 timeout、整批 batch 卡住、後來改 240 秒才順
- Step 5: try / except 包單次呼叫 — 一次失敗不該殺整個 batch、寫 error file 繼續下一題
- Step 6: 評分輸出嚴格 JSON + parser fallback — AI 即使說「嚴格 JSON」也會偶爾包 ``` markdown、parser 要剝 markdown / 抓第一個 {...} bracket
完整 Python runner 腳本 + 評審提示詞模板在下方的下載卡片裡、你可以拿去改 use case 直接跑。